
인덱스(Index)란?
데이터베이스의 테이블에 대한 검색속도를 향상시켜주는 자료구조
테이블의 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터를 정렬한 후 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다.
컬럼의 값과 물리적 주소를 (key, value)의 한 쌍으로 저장한다.
인덱스(Index)의 장단점
장점
- 테이블을 검색하는 속도와 성능 향상, 그에 따른 시스템의 전반적인 부하 줄일 수 있다.
- SELECT 외에도 UPDATE, DELETE의 성능이 함께 향상된다(수정과 삭제를 위해선 데이터 조회가 필요하기 때문).
단점
- 인덱스를 관리하기 위한 약 10% 추가 저장공간이 필요하다.
- 삽입, 삭제, 수정이 잦을 경우 인덱스 관리를 위한 추가 작업이 필요하므로 오히려 성능이 낮아질 수 있다.
- DELEAT는 인덱스를 삭제하는 것이아니라 사용하지 않음 상태로 남겨두기 때문에 수정이 잦을 경우 인덱스가 데이터보다 과도하게
커지고, 비대해진 인덱스 탓에 성능은 더 저하될 수 있다. - 전체 데이터의 10~15% 이상의 데이터를 처리하거나, 데이터의 형식에 따라 오히려 성능이 낮아질 수 있다.
인덱스(Index)를 사용하면 좋은 경우
- 규모가 큰 테이블
- 삽입(INSERT), 수정(UPDATE), 삭제(DELETE) 작업이 자주 발생하지 않는 컬럼
- WHERE나 ORDER BY, JOIN 등이 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
인덱스(Index)의 구조
인덱스는 배열이나 linked-list같은 형태가 아닌 이진탐색트리 형태로 주로 정렬되어있다.
B-tree
- 자식노드를 2개이상 가질 수 있는 트리
- 하나의 노드에 2개 이상의 데이터(key)가 들어갈 수 있으며, 항상 정렬된 상태로 저장
- 똑같이 두번 이동하더라도 이진탐색트리보다 더 많은 데이터를 탐색할 수 있음
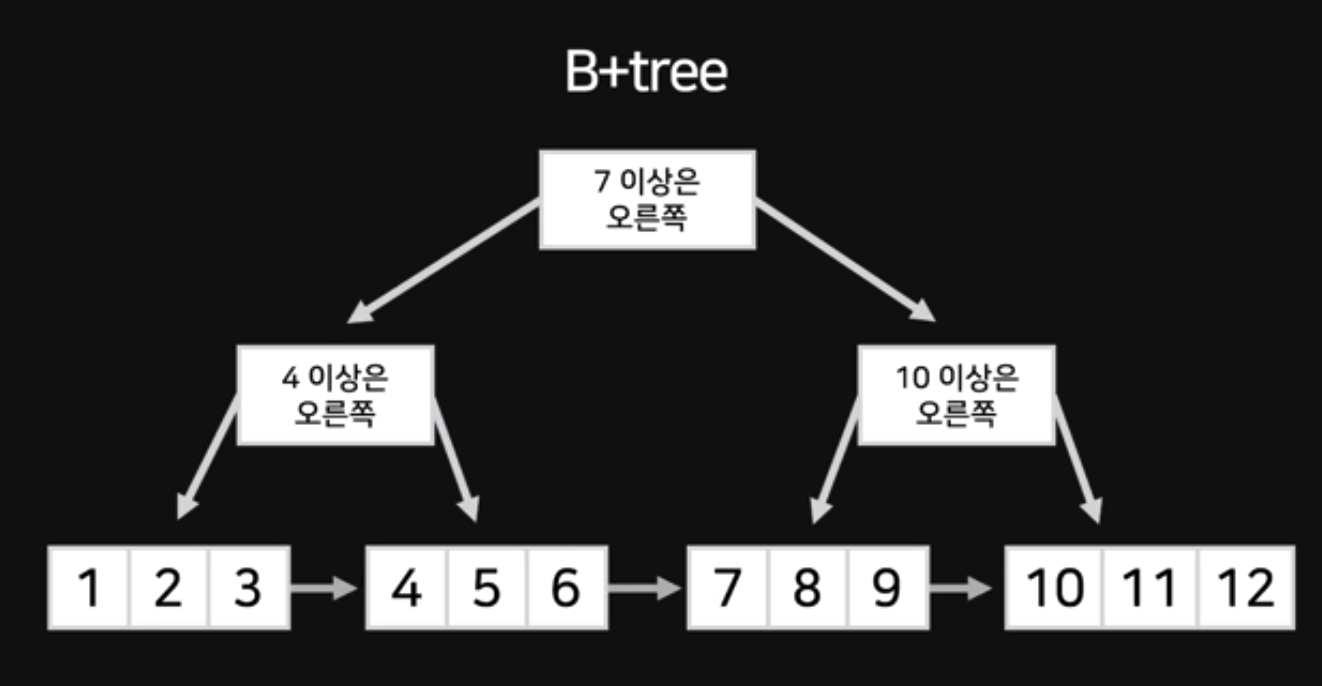
B+tree
- 맨아래 노드(leaf-node)에만 데이터 저장, 위(branch-node)에는 가이드 라인만 제공(key저장)
- 맨아래 노드끼리도 화살표로 연결해두어(linked-list) 범위 검색이 용이함
인덱스(Index) scan 방식
Full TABLE SCAN
: 테이블 전체 데이터를 읽어 조건에 맞는 데이터를 추출하는 방식
ROWID SCAN
: ROWID를 기준으로 데이터를 추출하는 방식. 단일 행에 접근하는 방식 중 가장 빠르다.
INDEX SCAN
1. Index range scan
: 특정범위의 인덱스를 탐색
: 인덱스를 통해 B+ Tree를 수직탐색 후, Leaf 블록을 필요한 범위까지 탐색하는 방식
2. Index Full Scan
: 인덱스 전체를 탐색
: 수직적 탐색 없이 인덱스 Leaf 노드들에 대해 전체 탐색하는 방식
3. Index Fast Full Scan
: 인덱스 구조를 무시하고 인덱스 전체를 multi block l/O 방식으로 스캔한다. (2번의 경우는 single block I/O)
: 즉, 물리적으로 디스크에 저장된 순서대로 인덱스 블록을 읽어 들임
: 인덱스 리프 노드가 갖는 연결 리스트 구조를 이용하지 않기 때문에 얻어진 결과 집합이 인덱스 키 순서대로 정렬되지 않음, 쿼리에 사용되는 모든 컬림이 인덱스 컬럼에 포함되어 있을 때만 사용 가능
4. Index Unique Scan
: 유일 인덱스를 사용하여 단 하나의 데이터를 추출하는 방식
: unique 인덱스를 통해 등치(=) 조건으로 탐색하는 경우 작동
: 수직적 탐색만으로 데이터를 찾는 방식
클러스터 인덱스(Cluster Index) & 논클러스터 인덱스(NonClustered Index)
cluster : 군중
: 인덱스와 데이터가 군집되어 있다면 clustered Index, 아니면 nonClustered Index
Clustered Index
클러스터 형 인덱스는 데이터가 테이블에 물리적으로 저장 되는 순서를 정의(설정)한다.
즉, 클러스터 형 인덱스는 특정 컬럼을 기준으로 데이터들을 직접 정렬시킨다.
- 검색속도를 향상
- 테이블 데이터는 오직 한 가지의 방법으로만 정렬되기 때문에 오직 테이블 당 하나의 클러스터 형 인덱스만 존재할 수 있다.
- 테이블을 생성할 때 특정 컬럼에 primary key를 지정했다면 자료가 자동으로 정렬된다.
- 새로운 데이터를 추가하면 정렬 기준에 따라 데이터들을 전부 이동시키고 중간에 삽입해야하므로 데이터 삽입 시 많은 비용 소모
NonClustered Index
논 클러스터 형 인덱스는 테이블에 저장 된 물리적인 순서에 따라 데이터를 정렬하지 않는다.
즉, 순서대로 정렬되어 있지 않다. 인덱스는 별도의 객체로 관리되며 데이터를 직접 정렬하지는 않지만 대신 포인터를 가지고 있다.
Reference
https://www.youtube.com/watch?v=iNvYsGKelYs
https://land-turtler.tistory.com/120
https://velog.io/@tothek/%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EA%B8%B0%EB%B3%B8-INDEX-SCAN%EC%A2%85%EB%A5%98
댓글